LangChain+ChatGLM模型自建及评测
前言
ChatGLM模型简介
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。
ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答,更多信息请参考博客。
为了方便下游开发者针对自己的应用场景定制模型,同时实现了基于 P-Tuning v2 的高效参数微调方法 (使用指南) ,INT4 量化级别下最低只需 7GB 显存即可启动微调。
LangChain简介
🤖️ 一种利用 langchain 思想实现的基于本地知识库的问答应用,期望建立一套对中文场景与开源模型支持友好、可离线运行的知识库问答解决方案。
💡 受 GanymedeNil 的项目 document.ai 和 AlexZhangji 创建的 ChatGLM-6B Pull Request 启发,建立了全流程可使用开源模型实现的本地知识库问答应用。现已支持使用 ChatGLM-6B 等大语言模型直接接入,或通过 fastchat api 形式接入 Vicuna, Alpaca, LLaMA, Koala, RWKV 等模型。
实现过程:过程包括加载文件 -> 读取文本 -> 文本分割 -> 文本向量化 -> 问句向量化 -> 在文本向量中匹配出与问句向量最相似的top k个 -> 匹配出的文本作为上下文和问题一起添加到prompt中 -> 提交给LLM生成回答。
1.搭建过程
飞浆平台搭建,待补充
2.效果评测
2.1 三条统计数据以表格形式导入知识库
select shop_code as "店铺编码", |
数据集:
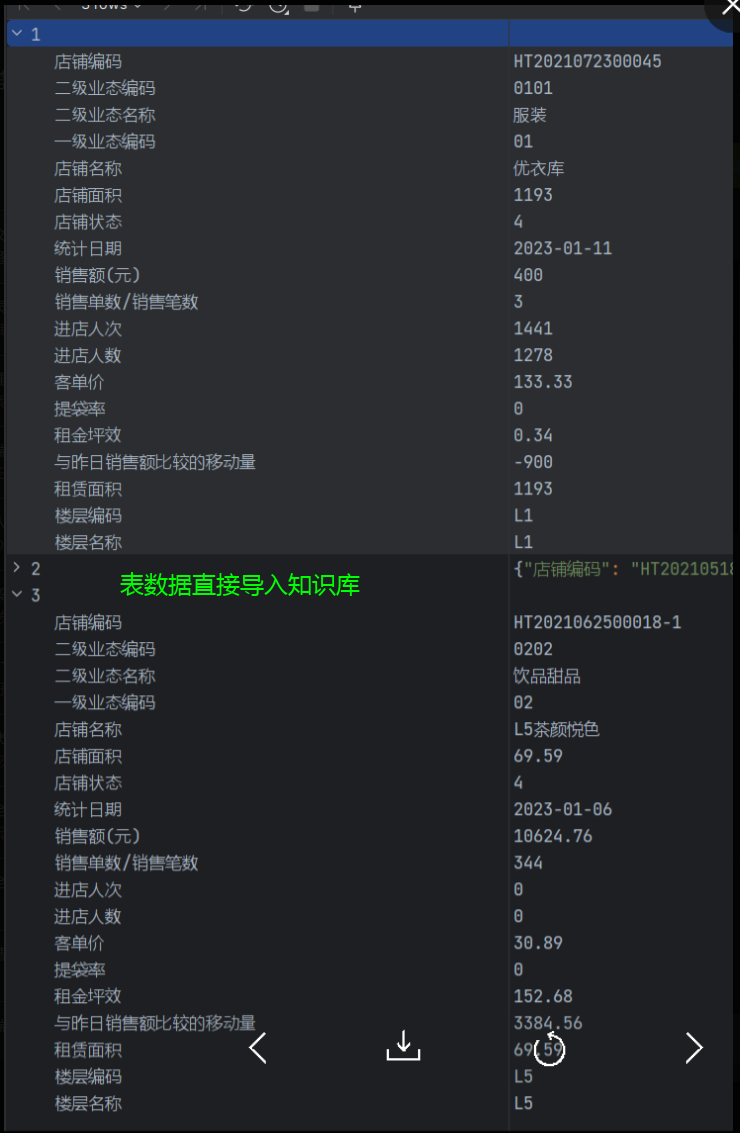
效果:

2.2 百条统计数据转换为描述语句+行号,导入知识库
select concat(row, '.', "t") |
数据集:

效果:

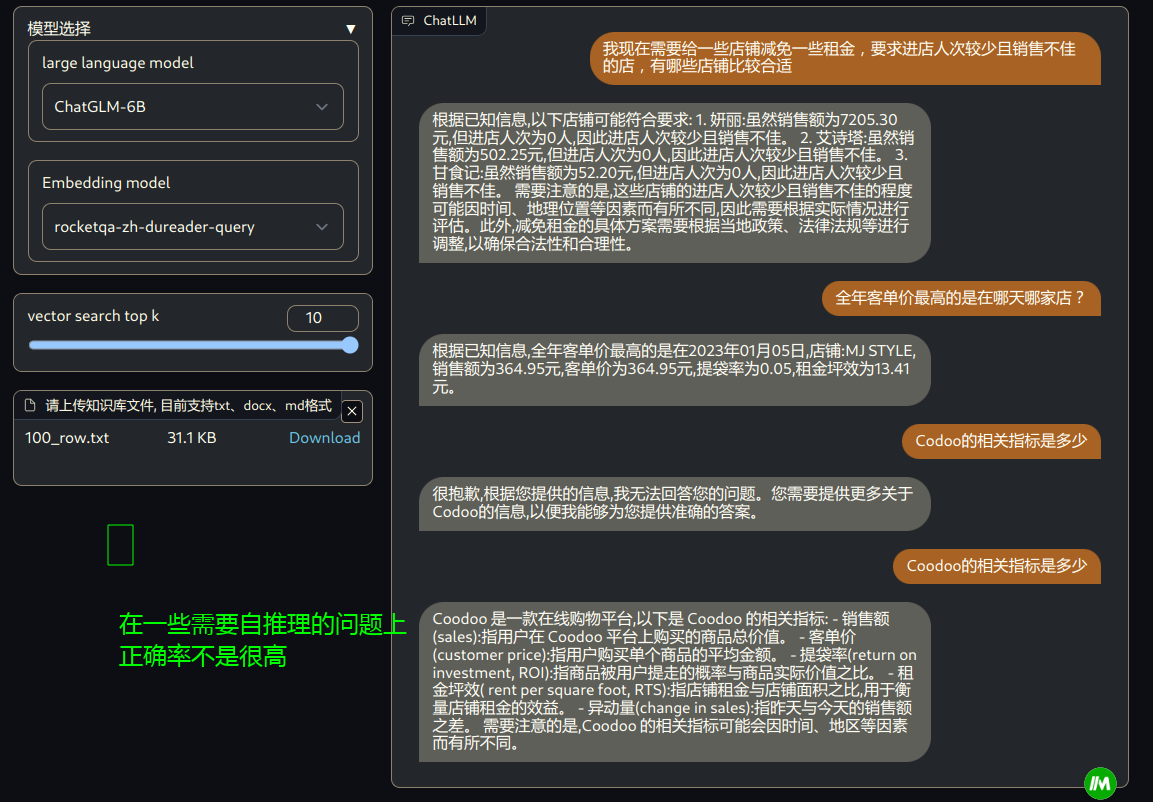
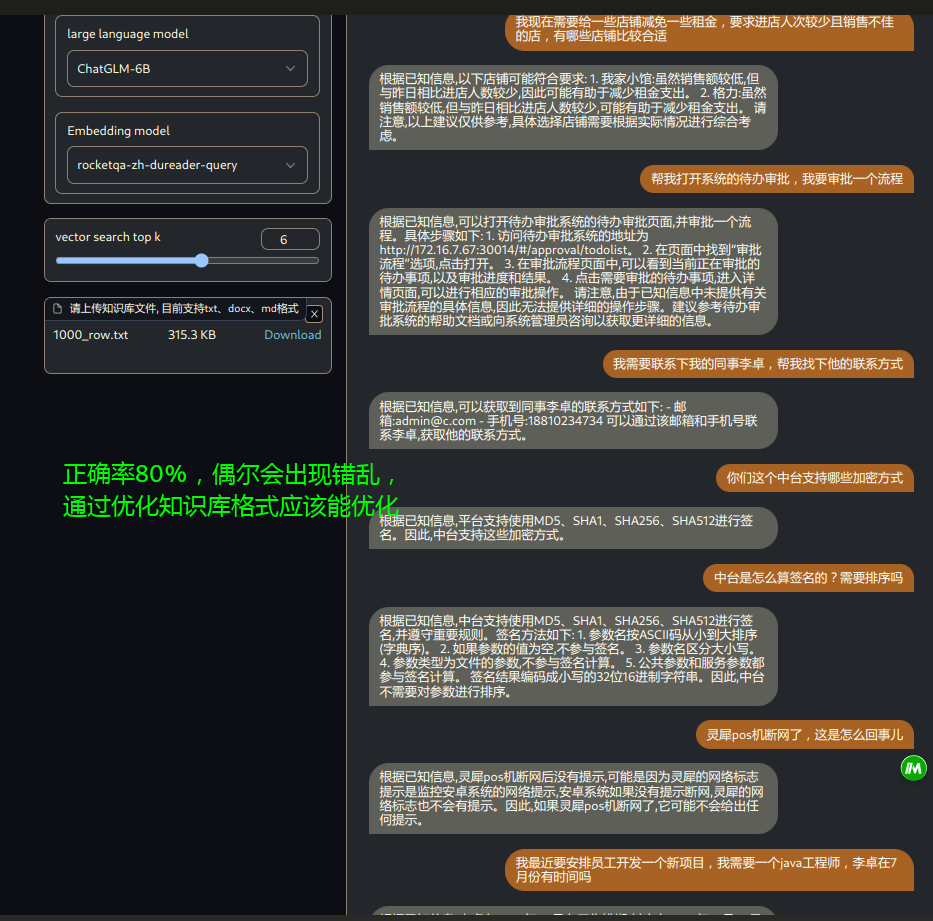
2.4 千条统计数据的基础上,加入其他知识信息,导入知识库
select name, email, phone_no, disable |
数据集:
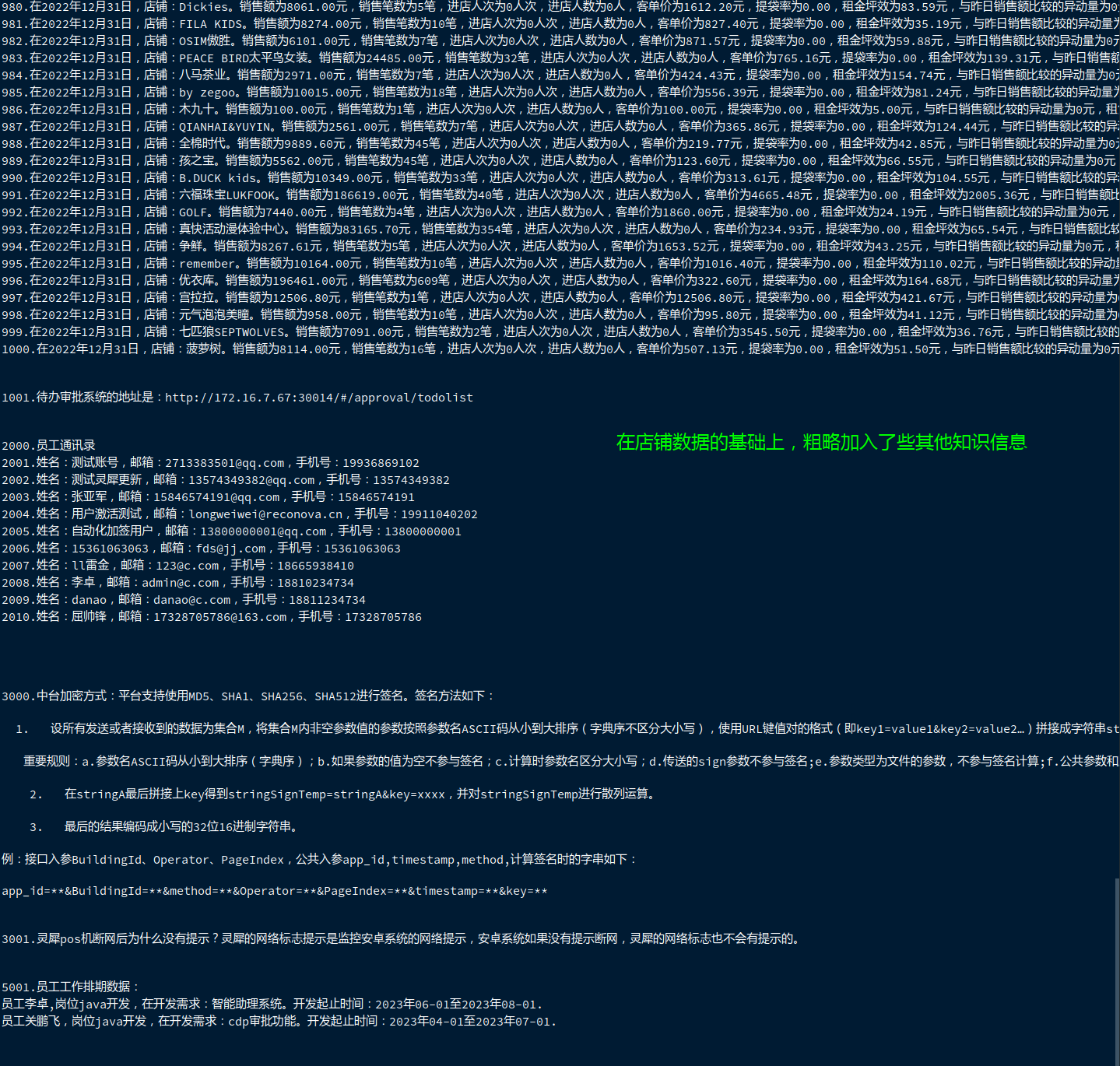
效果:
本文作者:Lee
本文地址: leeblog.icu/2023/06/24/
版权声明:本博客所有文章除特别声明外,均采用 CC 4.0 BY-NC-SA 许可协议。转载请注明出处!